
🎓 About Me
I’m a final-year Undergraduate student from The Chinese University of Hong Kong, Shenzhen, majoring in Computer Science and Engineering. My research focuses on embodied AI and robotics. My research interests lie at the intersection of large language models, robotics, and embodied intelligence. I’m particularly interested in continous learing of robot or VLM agent. My recent work includes VLA, World Model, Agentic AI, Memory Systems.
🔥 News
- 2026.02: 🎉🎉 Joined SenseTime as an Algorithm Intern focusing on world model.
- 2025.12: 🏆🏆 Awarded AY2024-2025 Academic Performance Scholarship: Class A (Top 1% GPA).
- 2025.04: 🎉🎉 One First autor paper accepted by IROS 2025.
- 2025.01: 🎉🎉 One paper accepted by NAACL 2025 Findings.
- 2024.12: 🏆🏆 Awarded AY2023-2024 Academic Performance Scholarship: Class A (Top 1% GPA).
📝 Selected Publications
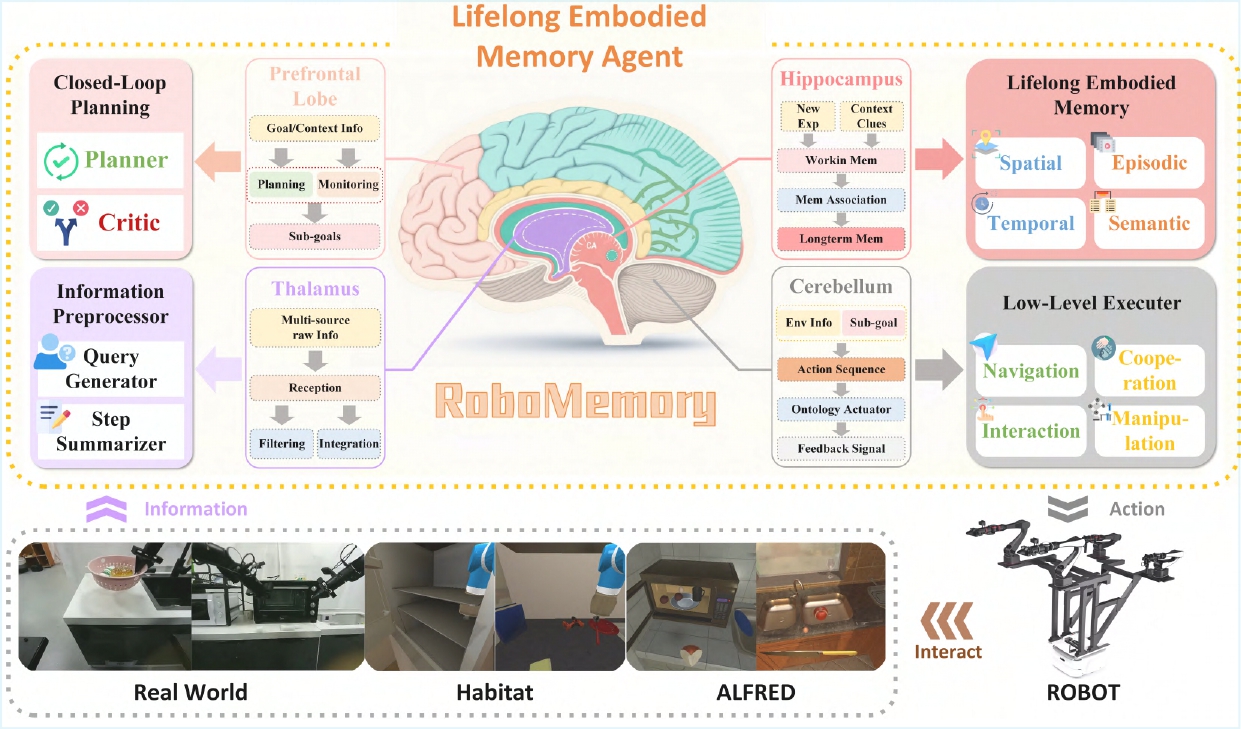
Mingcong Lei, Honghao Cai, Zezhou Cui, Liangchen Tan, Junkun Hong, Gehan Hu, Shuangyu Zhu, Yimou Wu, Shaohan Jiang, Ge Wang, Yuyuan Yang, Junyuan Tan, Zhenglin Wan, Zhen Li, Shuguang Cui, Yiming Zhao, Yatong Han

Weihao Tan, Changjiu Jiang, Yu Duan, Mingcong Lei, Li JiaGeng, Yitian Hong, Xinrun Wang, Bo An
CLEA: Closed-Loop Embodied Agent for Enhancing Task Execution in Dynamic Environments
Mingcong Lei, Ge Wang, Yiming Zhao, Zhixin Mai, Qing Zhao, Yao Guo, Zhen Li, Shuguang Cui, Yatong Han, Jinke Ren
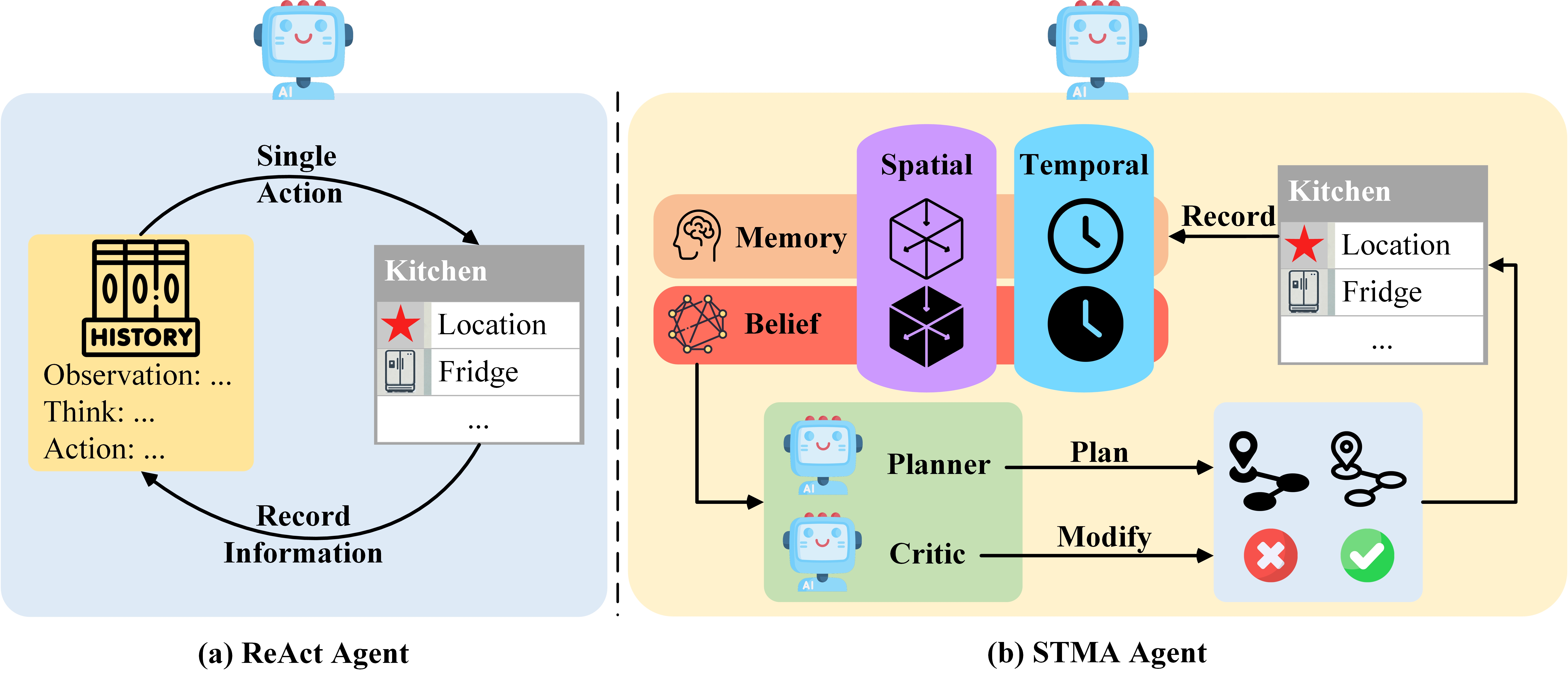
STMA: A Spatio-Temporal Memory Agent for Long-Horizon Embodied Task Planning
Mingcong Lei, Yiming Zhao, Ge Wang, Zhixin Mai, Shuguang Cui, Yatong Han, Jinke Ren
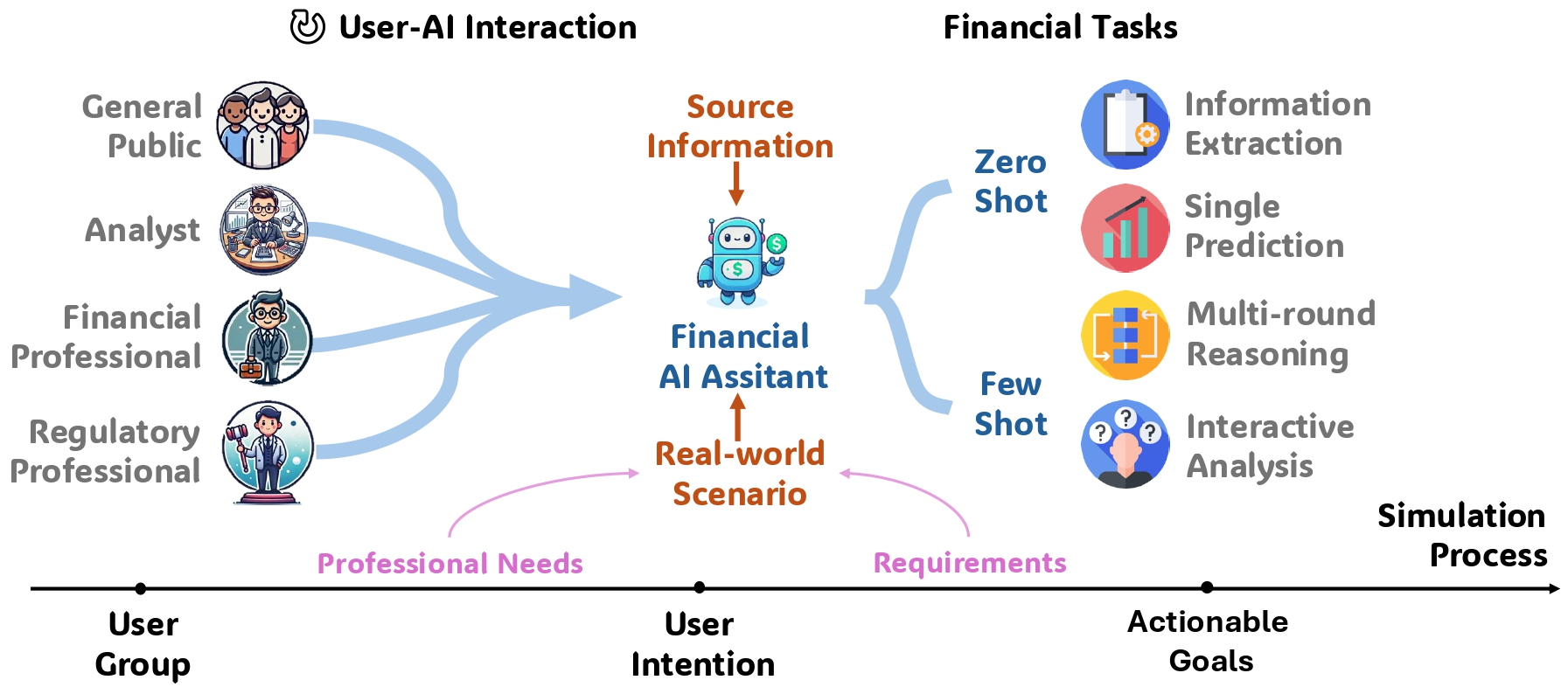
UCFE: A User-Centric Financial Expertise Benchmark for Large Language Models
Yuzhe Yang, Yifei Zhang, Yan Hu, Yilin Guo, Ruoli Gan, Yueru He, Mingcong Lei, Xiao Zhang, Haining Wang, Qianqian Xie, Jimin Huang, Honghai Yu, Benyou Wang
🎖 Honors and Awards
- 2024-2025 Academic Performance Scholarship: Class A (Year GPA top 1%)
- 2023-2024 Academic Performance Scholarship: Class A (Year GPA top 1%)
- 2024 MCM/ICM Meritorious Winner
- 2022-2025 Yearly Dean List Award (Outstanding Academic Performance, three consecutive years)
📖 Educations

|
Nanyang Technological University (Exchange) 2024.09 - 2024.12 Major: Computer Science CGPA: 4.75/5.0 |

|
The Chinese University of Hong Kong, Shenzhen 2022.09 - 2026.06 (expected) B.Eng. in Computer Science and Engineering CGPA: 3.90/4.0 (Rank: 7/129, Top 6%) MGPA: 4.0/4.0 (Rank: 1/129, Top 1%) |
💻 Internships

|
SenseTime 2026.02 - Present Algorithm Intern (World Model) Location: China |
👔 Services
- Reviewer of IROS/ICML/ICLR/AAAI/EMNLP